What is Artificial Intelligence?
Definition...
Artificial Intelligence is a branch of Science which deals with helping machines find solutions to complex problems in a more human-like fashion. This generally involves borrowing characteristics from human intelligence, and applying them as algorithms in a computer friendly way. A more or less flexible or efficient approach can be taken depending on the requirements established, which influences how artificial the intelligent behaviour appears.
AI is generally associated with Computer Science, but it has many important links with other fields such as Maths, Psychology, Cognition, Biology and Philosophy, among many others. Our ability to combine knowledge from all these fields will ultimately benefit our progress in the quest of creating an intelligent artificial being.
Why Artificial Intelligence?
Motivation...
Computers are fundamentally well suited to performing mechanical computations, using fixed programmed rules. This allows artificial machines to perform simple monotonous tasks efficiently and reliably, which humans are ill-suited to. For more complex problems, things get more difficult... Unlike humans, computers have trouble understanding specific situations, and adapting to new situations. Artificial Intelligence aims to improve machine behaviour in tackling such complex tasks.
Together with this, much of AI research is allowing us to understand our intelligent behaviour. Humans have an interesting approach to problem-solving, based on abstract thought, high-level deliberative reasoning and pattern recognition. Artificial Intelligence can help us understand this process by recreating it, then potentially enabling us to enhance it beyond our current capabilities.
When will Computers become truly Intelligent?
Limitations...
To date, all the traits of human intelligence have not been captured and applied together to spawn an intelligent artificial creature. Currently, Artificial Intelligence rather seems to focus on lucrative domain specific applications, which do not necessarily require the full extent of AI capabilities. This limit of machine intelligence is known to researchers as narrow intelligence.
There is little doubt among the community that artificial machines will be capable of intelligent thought in the near future. It's just a question of what and when... The machines may be pure silicon, quantum computers or hybrid combinations of manufactured components and neural tissue. As for the date, expect great things to happen within this century!
How does Artificial Intelligence work?
Technology...
There are many different approaches to Artificial Intelligence, none of which are either completely right or wrong. Some are obviously more suited than others in some cases, but any working alternative can be defended. Over the years, trends have emerged based on the state of mind of influencial researchers, funding opportunities as well as available computer hardware.
Over the past five decades, AI research has mostly been focusing on solving specific problems. Numerous solutions have been devised and improved to do so efficiently and reliably. This explains why the field of Artificial Intelligence is split into many branches, ranging from Pattern Recognition to Artificial Life, including Evolutionary Computation and Planning.
Who uses Artificial Intelligence?
Applications...
The potential applications of Artificial Intelligence are abundant. They stretch from the military for autonomous control and target identification, to the entertainment industry for computer games and robotic pets. Lets also not forget big establishments dealing with huge amounts of information such as hospitals, banks and insurances, who can use AI to predict customer behaviour and detect trends.
As you may expect, the business of Artificial Intelligence is becoming one of the major driving forces for research. With an ever growing market to satisfy, there's plenty of room for more personel. So if you know what you're doing, there's plenty of money to be made from interested big companies!
Where can I find out about Artificial Intelligence?
Information...
If you're interested in AI, you've come to the right place! The Artificial Intelligence Depot is a site purely dedicated to AI bringing you daily news and regular features, providing you with community interaction as well as an ever growing database of knowledge resources. Whether you are a complete beginner, experienced programmer, computer games hacker or academic researcher, you will find something to suit your needs here.
Once you've finished reading this page, the first thing you should do is visit the Artificial Intelligence Depot's main page. This deals with the daily Artificial Intelligence business, and contains links to useful resources. From now onwards you will always be taken to this main page, but you can always come back to this introduction page via the menu. If you need a quick guide to the site before you start, refer to our introduction for the AI Depot.
That said, you shoult not limit yourself to online information. Getting a good book on the subject is probably one of the smartest moves to make if you are really serious about Artificial Intelligence. A good starting point is the book called Artificial Intelligence: A Modern Approach, which covers important material from the ground upwards.
__________________________________________________________________________
Q. What is artificial intelligence?
A. It is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.
Q. Yes, but what is intelligence?
A. Intelligence is the computational part of the ability to achieve goals in the world. Varying kinds and degrees of intelligence occur in people, many animals and some machines.
Q. Isn't there a solid definition of intelligence that doesn't depend on relating it to human intelligence?
A. Not yet. The problem is that we cannot yet characterize in general what kinds of computational procedures we want to call intelligent. We understand some of the mechanisms of intelligence and not others.
Q. Is intelligence a single thing so that one can ask a yes or no question ``Is this machine intelligent or not?''?
A. No. Intelligence involves mechanisms, and AI research has discovered how to make computers carry out some of them and not others. If doing a task requires only mechanisms that are well understood today, computer programs can give very impressive performances on these tasks. Such programs should be considered ``somewhat intelligent''.
Q. Isn't AI about simulating human intelligence?
A. Sometimes but not always or even usually. On the one hand, we can learn something about how to make machines solve problems by observing other people or just by observing our own methods. On the other hand, most work in AI involves studying the problems the world presents to intelligence rather than studying people or animals. AI researchers are free to use methods that are not observed in people or that involve much more computing than people can do.
Q. What about IQ? Do computer programs have IQs?
A. No. IQ is based on the rates at which intelligence develops in children. It is the ratio of the age at which a child normally makes a certain score to the child's age. The scale is extended to adults in a suitable way. IQ correlates well with various measures of success or failure in life, but making computers that can score high on IQ tests would be weakly correlated with their usefulness. For example, the ability of a child to repeat back a long sequence of digits correlates well with other intellectual abilities, perhaps because it measures how much information the child can compute with at once. However, ``digit span'' is trivial for even extremely limited computers.
However, some of the problems on IQ tests are useful challenges for AI.
Q. What about other comparisons between human and computer intelligence?
Arthur R. Jensen [Jen98], a leading researcher in human intelligence, suggests ``as a heuristic hypothesis'' that all normal humans have the same intellectual mechanisms and that differences in intelligence are related to ``quantitative biochemical and physiological conditions''. I see them as speed, short term memory, and the ability to form accurate and retrievable long term memories.
Whether or not Jensen is right about human intelligence, the situation in AI today is the reverse.
Computer programs have plenty of speed and memory but their abilities correspond to the intellectual mechanisms that program designers understand well enough to put in programs. Some abilities that children normally don't develop till they are teenagers may be in, and some abilities possessed by two year olds are still out. The matter is further complicated by the fact that the cognitive sciences still have not succeeded in determining exactly what the human abilities are. Very likely the organization of the intellectual mechanisms for AI can usefully be different from that in people.
Whenever people do better than computers on some task or computers use a lot of computation to do as well as people, this demonstrates that the program designers lack understanding of the intellectual mechanisms required to do the task efficiently.
Q. When did AI research start?
A. After WWII, a number of people independently started to work on intelligent machines. The English mathematician Alan Turing may have been the first. He gave a lecture on it in 1947. He also may have been the first to decide that AI was best researched by programming computers rather than by building machines. By the late 1950s, there were many researchers on AI, and most of them were basing their work on programming computers.
Q. Does AI aim to put the human mind into the computer?
A. Some researchers say they have that objective, but maybe they are using the phrase metaphorically. The human mind has a lot of peculiarities, and I'm not sure anyone is serious about imitating all of them.
Q. What is the Turing test?
A. Alan Turing's 1950 article Computing Machinery and Intelligence [Tur50] discussed conditions for considering a machine to be intelligent. He argued that if the machine could successfully pretend to be human to a knowledgeable observer then you certainly should consider it intelligent. This test would satisfy most people but not all philosophers. The observer could interact with the machine and a human by teletype (to avoid requiring that the machine imitate the appearance or voice of the person), and the human would try to persuade the observer that it was human and the machine would try to fool the observer.
The Turing test is a one-sided test. A machine that passes the test should certainly be considered intelligent, but a machine could still be considered intelligent without knowing enough about humans to imitate a human.
Daniel Dennett's book Brainchildren [Den98] has an excellent discussion of the Turing test and the various partial Turing tests that have been implemented, i.e. with restrictions on the observer's knowledge of AI and the subject matter of questioning. It turns out that some people are easily led into believing that a rather dumb program is intelligent.
Q. Does AI aim at human-level intelligence?
A. Yes. The ultimate effort is to make computer programs that can solve problems and achieve goals in the world as well as humans. However, many people involved in particular research areas are much less ambitious.
Q. How far is AI from reaching human-level intelligence? When will it happen?
A. A few people think that human-level intelligence can be achieved by writing large numbers of programs of the kind people are now writing and assembling vast knowledge bases of facts in the languages now used for expressing knowledge.
However, most AI researchers believe that new fundamental ideas are required, and therefore it cannot be predicted when human level intelligence will be achieved.
Q. Are computers the right kind of machine to be made intelligent?
A. Computers can be programmed to simulate any kind of machine.
Many researchers invented non-computer machines, hoping that they would be intelligent in different ways than the computer programs could be. However, they usually simulate their invented machines on a computer and come to doubt that the new machine is worth building. Because many billions of dollars that have been spent in making computers faster and faster, another kind of machine would have to be very fast to perform better than a program on a computer simulating the machine.
Q. Are computers fast enough to be intelligent?
A. Some people think much faster computers are required as well as new ideas. My own opinion is that the computers of 30 years ago were fast enough if only we knew how to program them. Of course, quite apart from the ambitions of AI researchers, computers will keep getting faster.
Q. What about parallel machines?
A. Machines with many processors are much faster than single processors can be. Parallelism itself presents no advantages, and parallel machines are somewhat awkward to program. When extreme speed is required, it is necessary to face this awkwardness.
Q. What about making a ``child machine'' that could improve by reading and by learning from experience?
A. This idea has been proposed many times, starting in the 1940s. Eventually, it will be made to work. However, AI programs haven't yet reached the level of being able to learn much of what a child learns from physical experience. Nor do present programs understand language well enough to learn much by reading.
Q. Might an AI system be able to bootstrap itself to higher and higher level intelligence by thinking about AI?
A. I think yes, but we aren't yet at a level of AI at which this process can begin.
Q. What about chess?
A. Alexander Kronrod, a Russian AI researcher, said ``Chess is the Drosophila of AI.'' He was making an analogy with geneticists' use of that fruit fly to study inheritance. Playing chess requires certain intellectual mechanisms and not others. Chess programs now play at grandmaster level, but they do it with limited intellectual mechanisms compared to those used by a human chess player, substituting large amounts of computation for understanding. Once we understand these mechanisms better, we can build human-level chess programs that do far less computation than do present programs.
Unfortunately, the competitive and commercial aspects of making computers play chess have taken precedence over using chess as a scientific domain. It is as if the geneticists after 1910 had organized fruit fly races and concentrated their efforts on breeding fruit flies that could win these races.
Q. What about Go?
A. The Chinese and Japanese game of Go is also a board game in which the players take turns moving. Go exposes the weakness of our present understanding of the intellectual mechanisms involved in human game playing. Go programs are very bad players, in spite of considerable effort (not as much as for chess). The problem seems to be that a position in Go has to be divided mentally into a collection of subpositions which are first analyzed separately followed by an analysis of their interaction. Humans use this in chess also, but chess programs consider the position as a whole. Chess programs compensate for the lack of this intellectual mechanism by doing thousands or, in the case of Deep Blue, many millions of times as much computation.
Sooner or later, AI research will overcome this scandalous weakness.
Q. Don't some people say that AI is a bad idea?
A. The philosopher John Searle says that the idea of a non-biological machine being intelligent is incoherent. He proposes the Chinese room argument. www-formal.stanford.edu/jmc/chinese.html The philosopher Hubert Dreyfus says that AI is impossible. The computer scientist Joseph Weizenbaum says the idea is obscene, anti-human and immoral. Various people have said that since artificial intelligence hasn't reached human level by now, it must be impossible. Still other people are disappointed that companies they invested in went bankrupt.
Q. Aren't computability theory and computational complexity the keys to AI? [Note to the layman and beginners in computer science: These are quite technical branches of mathematical logic and computer science, and the answer to the question has to be somewhat technical.]
A. No. These theories are relevant but don't address the fundamental problems of AI.
In the 1930s mathematical logicians, especially Kurt Gödel and Alan Turing, established that there did not exist algorithms that were guaranteed to solve all problems in certain important mathematical domains. Whether a sentence of first order logic is a theorem is one example, and whether a polynomial equations in several variables has integer solutions is another. Humans solve problems in these domains all the time, and this has been offered as an argument (usually with some decorations) that computers are intrinsically incapable of doing what people do. Roger Penrose claims this. However, people can't guarantee to solve arbitrary problems in these domains either.
In the 1960s computer scientists, especially Steve Cook and Richard Karp developed the theory of NP-complete problem domains. Problems in these domains are solvable, but seem to take time exponential in the size of the problem. Which sentences of propositional calculus are satisfiable is a basic example of an NP-complete problem domain. Humans often solve problems in NP-complete domains in times much shorter than is guaranteed by the general algorithms, but can't solve them quickly in general.
What is important for AI is to have algorithms as capable as people at solving problems. The identification of subdomains for which good algorithms exist is important, but a lot of AI problem solvers are not associated with readily identified subdomains.
The theory of the difficulty of general classes of problems is called computational complexity. So far this theory hasn't interacted with AI as much as might have been hoped. Success in problem solving by humans and by AI programs seems to rely on properties of problems and problem solving methods that the neither the complexity researchers nor the AI community have been able to identify precisely.
Algorithmic complexity theory as developed by Solomonoff, Kolmogorov and Chaitin (independently of one another) is also relevant. It defines the complexity of a symbolic object as the length of the shortest program that will generate it. Proving that a candidate program is the shortest or close to the shortest is an unsolvable problem, but representing objects by short programs that generate them should sometimes be illuminating even when you can't prove that the program is the shortest.
Branches of AI
Q. What are the branches of AI?
A. Here's a list, but some branches are surely missing, because no-one has identified them yet. Some of these may be regarded as concepts or topics rather than full branches.
logical AI
What a program knows about the world in general the facts of the specific situation in which it must act, and its goals are all represented by sentences of some mathematical logical language. The program decides what to do by inferring that certain actions are appropriate for achieving its goals. The first article proposing this was [McC59]. [McC89] is a more recent summary. [McC96b] lists some of the concepts involved in logical aI. [Sha97] is an important text.
search
AI programs often examine large numbers of possibilities, e.g. moves in a chess game or inferences by a theorem proving program. Discoveries are continually made about how to do this more efficiently in various domains.
pattern recognition
When a program makes observations of some kind, it is often programmed to compare what it sees with a pattern. For example, a vision program may try to match a pattern of eyes and a nose in a scene in order to find a face. More complex patterns, e.g. in a natural language text, in a chess position, or in the history of some event are also studied. These more complex patterns require quite different methods than do the simple patterns that have been studied the most.
representation
Facts about the world have to be represented in some way. Usually languages of mathematical logic are used.
inference
From some facts, others can be inferred. Mathematical logical deduction is adequate for some purposes, but new methods of non-monotonic inference have been added to logic since the 1970s. The simplest kind of non-monotonic reasoning is default reasoning in which a conclusion is to be inferred by default, but the conclusion can be withdrawn if there is evidence to the contrary. For example, when we hear of a bird, we man infer that it can fly, but this conclusion can be reversed when we hear that it is a penguin. It is the possibility that a conclusion may have to be withdrawn that constitutes the non-monotonic character of the reasoning. Ordinary logical reasoning is monotonic in that the set of conclusions that can the drawn from a set of premises is a monotonic increasing function of the premises. Circumscription is another form of non-monotonic reasoning.
common sense knowledge and reasoning
This is the area in which AI is farthest from human-level, in spite of the fact that it has been an active research area since the 1950s. While there has been considerable progress, e.g. in developing systems of non-monotonic reasoning and theories of action, yet more new ideas are needed. The Cyc system contains a large but spotty collection of common sense facts.
learning from experience
Programs do that. The approaches to AI based on connectionism and neural nets specialize in that. There is also learning of laws expressed in logic. [Mit97] is a comprehensive undergraduate text on machine learning. Programs can only learn what facts or behaviors their formalisms can represent, and unfortunately learning systems are almost all based on very limited abilities to represent information.
planning
Planning programs start with general facts about the world (especially facts about the effects of actions), facts about the particular situation and a statement of a goal. From these, they generate a strategy for achieving the goal. In the most common cases, the strategy is just a sequence of actions.
epistemology
This is a study of the kinds of knowledge that are required for solving problems in the world.
ontology
Ontology is the study of the kinds of things that exist. In AI, the programs and sentences deal with various kinds of objects, and we study what these kinds are and what their basic properties are. Emphasis on ontology begins in the 1990s.
heuristics
A heuristic is a way of trying to discover something or an idea imbedded in a program. The term is used variously in AI. Heuristic functions are used in some approaches to search to measure how far a node in a search tree seems to be from a goal. Heuristic predicates that compare two nodes in a search tree to see if one is better than the other, i.e. constitutes an advance toward the goal, may be more useful. [My opinion].
genetic programming
Genetic programming is a technique for getting programs to solve a task by mating random Lisp programs and selecting fittest in millions of generations. It is being developed by John Koza's group and here's a tutorial.
Applications of AI
Q. What are the applications of AI?
A. Here are some.
game playing
You can buy machines that can play master level chess for a few hundred dollars. There is some AI in them, but they play well against people mainly through brute force computation--looking at hundreds of thousands of positions. To beat a world champion by brute force and known reliable heuristics requires being able to look at 200 million positions per second.
speech recognition
In the 1990s, computer speech recognition reached a practical level for limited purposes. Thus United Airlines has replaced its keyboard tree for flight information by a system using speech recognition of flight numbers and city names. It is quite convenient. On the the other hand, while it is possible to instruct some computers using speech, most users have gone back to the keyboard and the mouse as still more convenient.
understanding natural language
Just getting a sequence of words into a computer is not enough. Parsing sentences is not enough either. The computer has to be provided with an understanding of the domain the text is about, and this is presently possible only for very limited domains.
computer vision
The world is composed of three-dimensional objects, but the inputs to the human eye and computers' TV cameras are two dimensional. Some useful programs can work solely in two dimensions, but full computer vision requires partial three-dimensional information that is not just a set of two-dimensional views. At present there are only limited ways of representing three-dimensional information directly, and they are not as good as what humans evidently use.
expert systems
A ``knowledge engineer'' interviews experts in a certain domain and tries to embody their knowledge in a computer program for carrying out some task. How well this works depends on whether the intellectual mechanisms required for the task are within the present state of AI. When this turned out not to be so, there were many disappointing results. One of the first expert systems was MYCIN in 1974, which diagnosed bacterial infections of the blood and suggested treatments. It did better than medical students or practicing doctors, provided its limitations were observed. Namely, its ontology included bacteria, symptoms, and treatments and did not include patients, doctors, hospitals, death, recovery, and events occurring in time. Its interactions depended on a single patient being considered. Since the experts consulted by the knowledge engineers knew about patients, doctors, death, recovery, etc., it is clear that the knowledge engineers forced what the experts told them into a predetermined framework. In the present state of AI, this has to be true. The usefulness of current expert systems depends on their users having common sense.
heuristic classification
One of the most feasible kinds of expert system given the present knowledge of AI is to put some information in one of a fixed set of categories using several sources of information. An example is advising whether to accept a proposed credit card purchase. Information is available about the owner of the credit card, his record of payment and also about the item he is buying and about the establishment from which he is buying it (e.g., about whether there have been previous credit card frauds at this establishment).
More questions
Q. How is AI research done?
A. AI research has both theoretical and experimental sides. The experimental side has both basic and applied aspects.
There are two main lines of research. One is biological, based on the idea that since humans are intelligent, AI should study humans and imitate their psychology or physiology. The other is phenomenal, based on studying and formalizing common sense facts about the world and the problems that the world presents to the achievement of goals. The two approaches interact to some extent, and both should eventually succeed. It is a race, but both racers seem to be walking.
Q. What should I study before or while learning AI?
A. Study mathematics, especially mathematical logic. The more you learn about science in general the better. For the biological approaches to AI, study psychology and the physiology of the nervous system. Learn some programming languages--at least C, Lisp and Prolog. It is also a good idea to learn one basic machine language. Jobs are likely to depend on knowing the languages currently in fashion. In the late 1990s, these include C++ and Java.
Q. What is a good textbook on AI?
A. Artificial Intelligence by Stuart Russell and Peter Norvig, Prentice Hall is the most commonly used textbbook in 1997. The general views expressed there do not exactly correspond to those of this essay. Artificial Intelligence: A New Synthesis by Nils Nilsson, Morgan Kaufman, may be easier to read. Some people prefer Computational Intelligence by David Poole, Alan Mackworth and Randy Goebel, Oxford, 1998.
Q. What organizations and publications are concerned with AI?
A. The American Association for Artificial Intelligence (AAAI), the European Coordinating Committee for Artificial Intelligence (ECCAI) and the Society for Artificial Intelligence and Simulation of Behavior (AISB) are scientific societies concerned with AI research. The Association for Computing Machinery (ACM) has a special interest group on artificial intelligence SIGART.
Tuesday, June 28, 2005
Monday, June 27, 2005
Event Bubbling in ASP.NET : Kaushal Patel
Introduction
The DataGrid control, as you likely know, can easily be configured to add a column of buttons. By adding a ButtonColumn, whenever
one of the DataGrid's buttons in the column is clicked, the Web page posts back and the DataGrid's
event fires. In fact, the same behavior can be noted if you manually add a Button or LinkButton control into a DataGrid
TemplateColumn, as the ButtonColumn class simply adds a Button (or LinkButton) Web control to each row of the DataGrid.
The DataGrid control, as you likely know, can easily be configured to add a column of buttons. By adding a ButtonColumn, whenever
one of the DataGrid's buttons in the column is clicked, the Web page posts back and the DataGrid's
ItemCommandevent fires. In fact, the same behavior can be noted if you manually add a Button or LinkButton control into a DataGrid
TemplateColumn, as the ButtonColumn class simply adds a Button (or LinkButton) Web control to each row of the DataGrid.
When the Button (or LinkButton) is clicked, its Command event is raised. But how does the DataGrid know when
this event has been raised so that it can raise its ItemCommand event in response? The answer is through a
process referred to as event bubbling. Event bubbling is the process of moving an event up the control hierarchy,
from a control low in the hierarchy - such as a Button within the row of a DataGrid - and percolating it up to an ancestor
control - such as the DataGrid. Once the ancestor control has learned of the event it can respond however it sees fit; in
the DataGrid's case, the DataGrid "swallows" the Button's Command event (that is, it stops the bubbling) and
raises its own ItemCommand event in response.
In this article we'll look at how, precisely, event bubbling works in ASP.NET. Event bubbling is a technique that all
server control developers should be aware of. Additionally, it can be used as a means to pass event information from a
User Control to its parent page, as discussed in Handle
Events from Web User Controls (although personally I find it simpler to just use the technique of having the User Control
raise its own events through the standard event firing syntax as discussed at
An Extensive
Examination of User Controls). Read on to learn more!
Understanding the Control Hierarchy
All ASP.NET pages are represented in code as a hierarchy of controls. While ASP.NET page developers are accustomed to working
in terms of the Visual Studio .NET designer and HTML and Web control syntax, this markup is automatically converted into a
programmatically-created control hierarchy when an ASP.NET page is first visited (or first visited after a change to its
.aspx page's content). To better understand this process, let me refer to a previous article of mine,Understanding ASP.NET View State:
All ASP.NET server controls can have a parent control, along with a variable number of child controls. TheSystem.Web.UI.Pageclass is derived from the base control class (System.Web.UI.Control), and
therefore also can have a set of child controls. The top-level controls declared in an ASP.NET Web page's HTML portion are
the direct children of the autogeneratedPageclass. Web controls can also be nested inside one another. For
example, most ASP.NET Web pages contain a single server-side Web Form, with multiple Web controls inside the Web Form. The
Web Form is an HTML control (System.Web.UI.HtmlControls.HtmlForm). Those Web controls inside the Web Form are
children of the Web Form.
Since server controls can have children, and each of their children may have children, and so on, a control and its
descendents form a tree of controls. This tree of controls is called the control hierarchy. The root of the control
hierarchy for an ASP.NET Web page is thePage-derived class that is autogenerated by the ASP.NET engine.
Whew! Those last few paragraphs may have been a bit confusing, as this is not the easiest subject to discuss or digest. To
clear out any potential confusion, let's look at a quick example. Imagine you have an ASP.NET Web page with the following HTML
portion:
<html>
<body>
<h1>Welcome to my Homepage!</h1>
<form runat="server">
What is your name?
<asp:TextBox runat="server" ID="txtName"></asp:TextBox>
<br />What is your gender?
<asp:DropDownList runat="server" ID="ddlGender">
<asp:ListItem Select="True" Value="M">Male</asp:ListItem>
<asp:ListItem Value="F">Female</asp:ListItem>
<asp:ListItem Value="U">Undecided</asp:ListItem>
</asp:DropDownList>
<br />
<asp:Button runat="server" Text="Submit!"></asp:Button>
</form>
</body>
</html>
When this page is first visited, a class will be autogenerated that contains code to programmatically build up the control
hierarchy. The control hierarchy for this example [is shown below:]
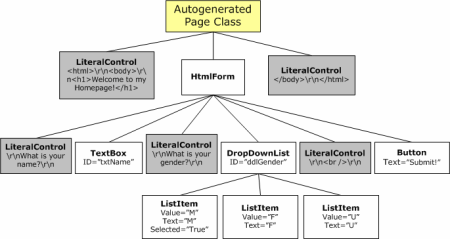
This concept of a control hierarchy works just the same with a DataGrid. Specifically, a DataGrid contains a child control
for each of its rows. Each of these row controls contains a child for each of its columns. And each column control may
contain further controls. For ButtonColumns, the column control would contain a single child control - either a Button or
LinkButton control. For a TemplateColumn, the column control would contain its own hierarchy of children that composed the
HTML markup and Web controls specified in the template.
For example, imagine we had a DataGrid with two columns, a ButtonColumn and a BoundColumn. When binding the DataGrid to
a DataSource with three records, the DataGrid's control hierarchy might look like the following:
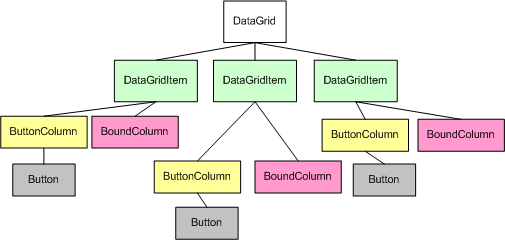
Bubbling Basics
When one of the DataGrid's Buttons are clicked, the Button's Command event is fired. When this happens we
also want to have the DataGrid's ItemCommand event fire, but as the above figure illustrates, there is a bit
of distance between the Button instance that was clicked and the DataGrid control. Event bubbling is employed to percolate
the event from the Button control up to the DataGrid, where the ItemCommand event can be raised in response.
Event bubbling works using two protected methods of the Control class:
RaiseBubbleEvent(source, eventArgs)- when called, a specified event's information is
bubbled up to control's parent. The source parameter is typically a reference to the object doing the bubbling (the
actual Button control in the DataGrid example), whereas theeventArgscontains information about the event
being bubbled (in the DataGrid example, the Button'sCommandEventArgsinformation is percolated up, which includes
the Button'sCommandNameandCommandArgumentparameters).OnBubbleEvent(source, eventArgs)- when an event is bubbled up to a control, the control'sOnBubbleEvent()method fires. A control in the hierarchy may override this method to do some custom
processing on the bubbled event. In the DataGrid's case, theOnBubbleEvent()method checks to see if
aCommandEventArgsinstance is being bubbled up. If so, it raises its ownItemCommandevent.
(This is a slight simplification of how things really work with the DataGrid.)
TheOnBubbleEvent()method returns a Boolean value that indicates if bubbling of the event should continue.
IfOnBubbleEvent()returns False, the event continues to bubble up the hierarchy; if it returns True, the
bubbling of that event ends. By default, a control'sOnBubbleEvent()returns False, thereby allowing event
bubbling to progress unimpeded.
To demonstrate event bubbling, image that the Button in the third
DataGrid row is clicked. Clicking the Button causes a postback and raises the appropriate Button control's Click
event handler. The Button (and LinkButton) Web control's are coded such that when their Command event is fired,
the event details are bubbled up the hierarchy. Specifically, the OnCommand() method in the Button and LinkButton
classes looks as follows (comments added by yours truly):
|
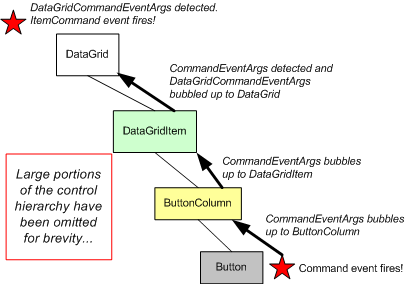
This event is then bubbled up to the ButtonColumn, calling its OnBubbleEvent() method, which, by default, does
nothing, thereby letting the bubbling continue. Following that, the DataGridItem's OnBubbleEvent() method is
called. The DataGridItem's OnBubbleEvent() checks to see if a CommandEventArgs object is being bubbled
up and, if so, it crafts an instance of the DataGridCommandEventArgs object based on the passed-inCommandEventArgs object. This new type is then bubbled up to its parent (the DataGrid) and event bubbling is
ceased. Here's the code from the DataGridItem's OnBubbleEvent() method:
|
Finally, in the DataGrid's OnBubbleEvent() method a check is made to see if a DataGridCommandEventArgs
object has been bubbled up. If so, it halts the bubbling and raises its ItemCommand event. (Note that the
DataGrid's OnBubbleEvent() method is a bit more complex than the DataGridItem's because the DataGrid
might raise a number of events based on the CommandName value in the DataGridCommandEventArgs object.
(For example, a CommandName of Edit raises the EditCommand event, a CommandName of Update
raises the UpdateCommand event, and so on. Of course, regardless of the CommandName the ItemCommand
always fires.)
The following figure depicts the chain of events just described:
Conclusion
In this article we saw how event bubbling is used to percolate events up the control hierarchy. This technique is an
invaluable one for control developers creating composite controls whose contents cannot be determined until runtime. The most
common Web control that fits into this class is the DataGrid, although both the DataList and Repeater use event bubbling in
a similar manner. For more information on creating these types of controls, along with a further discussion on event bubbling,
be sure to read Building
DataBound Templated Custom ASP.NET Server Controls.
Wednesday, June 22, 2005
Contract First Web Services Interoperability between Microsoft .NET and IBM WebSphere
Introduction
As Web service adoption increases, vendors are striving to add more features and standards into their frameworks to enable richer and more robust communication between systems. As organizations spend more time and money investigating how best to leverage Web services and its enabling technologies, they should be aware of the strengths and limitations of the technology—specifically, those related to developer agility, maintainability and interoperability. This paper specifically focuses on interoperability and takes as a starting point, interoperability between the Microsoft .NET Framework and IBM WebSphere via Web services. The goal of this
whitepaper and the accompanying sample is to show developers of each platform how to integrate with the other platform. More specifically we will look into Microsoft's .NET Platform and IBM's WebSphere Platform. The
samples demonstrate basic techniques and principles that are reusable across all projects where cross-platform interoperability via Web services is required.
Interoperability Sample Contents
The sample contains:
- Web service sample code
- Web services and Web service clients written in both Java and C# for three distinct service interfaces:
- Web Service 1: This demonstrates a simple addition Web service and is intended to familiarize you with the relevant toolkits and platforms.
- Web Service 2: This demonstrates passing complex object types between the two platforms.
- Web Service 3: This demonstrates one design pattern for building extensible Web services to handle cases where data mappings are subject to change.
- Each Web service demonstrates heterogeneous interoperability. By changing one setting in the Web service client, the Web service client can either communicate with the .NET Web service or the WebSphere Web service.
- In this simple example, database access is not required to run each Web service and client.
- In this document, we will go into detail about how to build Web Service 1 from first principles. We do not go into the same level of detail for Web Services 2 and 3.
- This whitepaper that talks about each of the Web services in detail and their design.
The techniques and concepts discussed in this article are general, and apply
to connecting platforms from any two vendors. However the samples were developed and tested only with the pairing of the Microsoft .NET Framework and the IBM WebSphere SDK for Web Services.
Prerequisites and Required Software
This interoperability article (and the related sample) assumes that the reader is familiar with the basics of both the .NET Framework and ASP.NET and the IBM WebSphere Application Server. Web Service 1 is for developers who have never created Web services before or who have not experienced both platforms. Even if you are familiar with Web services and both platforms involved we recommend that you at least review the Web Service 1 documentation as it contains useful hints and tips that are not covered in Web Services 2 and 3.
Software Requirements
The following software was used to create and test the samples.
- Microsoft Windows XP Professional SP1
- Microsoft Internet Information Services 5.1
If you do not have any of the Java software, it is crucial that you install the required software in this order:
- Sun Java SDK v1.4
- Eclipse v2.1.3
- WSDK v5.1
- JWSDP v1.3
- Eclipse requires a Java SDK, and while the WSDK includes one, WSDK requires Eclipse to be present first!
- More information about setup can be found in the README file in the interoperability samples
download.
Why Web Services?
Web services as an application technology have been with us for many years. Long before organizations and companies created the standards for Web services, Business Analysts, Architects and Software Engineers realized that their company's data was spread across many systems that needed to talk to each other. Previous attempts to link applications together using RPC based technologies such as RMI, DCOM, and other platform-specific inter-connection mechanisms had typically failed due to the wide variety of vendors and platforms that were in use across organizations. These approaches also failed as they were not suited to Internet use where responses could be slow or non-existent. The alternative approaches using message queues, PUT/GET verbs, and manual message marshalling had problems with maintainability and programmer productivity. Hence, developers turned to using some common standards and protocols, namely XML and HTTP.
When engineers started building applications that talked to each other, XML was chosen because of its ubiquitous use and support across all platforms. HTTP was chosen due its wide adoption and its ability to traverse firewalls. Vendors such as Microsoft and IBM started building frameworks to support these development efforts and to make the job of the developer easier. The frameworks achieve this by removing the burden of XML serialization and de-serialization and by providing the common infrastructure pieces such as the code required to make connections between systems. With the birth of Web services came the promise of simpler, easier integration between heterogeneous systems and applications. Vendors, using Web services as a catalyst, are now rallying around the concept of Service Oriented Architecture where individual solutions, which may still be built (justifiably) using proprietary RPC protocols such as RMI and DCOM, can be connected together to enable real time data to flow across the enterprise.
So the benefits and potential for integration exists, but, in practice, most developers find that creating interoperable Web services is quite a challenge. There are many hidden dangers in creating even the simplest of Web services, such as conflicting types or unsupported features. Our first sample will show you one example of an interoperable Web service and walk you through the process of designing and creating such a Web service.
Web Service 1: Addition
The first sample demonstrates the basics of interoperable Web service. It is a simple addition Web service that accepts two integers from the client and returns the sum of the two numbers.
The following high-level diagram depicts what the architecture of this Web service looks like:

Figure 1. High-level architecture of Web Service 1
Which Comes First, the Implementation or the Interface?
The most common approach when building Web services, and the one demonstrated most often and supported best by tools, is to "infer" a Web service interface from an existing implementation. A developer might write:
public int Add(int x, int y) {
return x+y;
}
In ASP.NET, exposing this as a Web service is as simple as adding a
WebMethod attribute to the code. This approach is often called "Implementation First" or "Code First", because the Web service interface, formally described in a Web Service Description Language (WSDL) document, is derived from the implementation.

Figure 2. Implementation First Web service development
With the Implementation First Web service development approach, you start off by writing code for your Web service (see #1 in Figure 2). After you compile, the Web services framework uses your code to dynamically generate a WSDL file (see #2). When clients request your Web service definition, they retrieve the generated WSDL and then create the client proxy based on that definition (see #3).
For example, in ASP.NET, the WSDL can be dynamically generated from an implementation with the URL like so:
http://hostname:port/Service1.asmx?WSDL
When the .NET runtime detects the WSDL parameter in the request, it uses reflection on the code decorated with the WebMethod attribute to dynamically generate an operation in the WSDL file to describe the underlying service.
This implementation approach works very well and is quite simple, but can introduce a few problems, especially in scenarios where the Web service is used to connect heterogeneous systems. For example, in the Implementation First approach it is possible to include platform-specific types in the Web service. .NET DataSets and Java Vectors are platform specific types that can't be represented easily in other platforms. This is because there is currently no single well-defined mapping between such platform-specific types and XML. Just because a .NET client can recognize a blob of XML as a Dataset, it doesn't mean a Web service client written in Java can do the same. Interoperability problems arise as a result.
The W3C XML Schema standard defines a number of built-in data types, among them string, integers of various sizes, Boolean, single- and double-precision floating point, dateTime, and others. Each application platform also supports a set of its own data types. The intersection of these data type sets defines the types that will be most interoperable across different platforms. If you start with XML Schema types, it is easy to map to platform types, but if you start with platform types there may not always be a mapping to an XML Schema type. For example, XML Schema integers, strings, Booleans, and float all map nicely to the corresponding data types in .NET or Java. However, Vectors and Hashtables are native types to individual platforms and are not part of the XML schema official types. See the XML Schema data types specifications for more information on the supported data types.
Most Web services runtimes (including the one built-in to the .NET Framework and the WSDK) can map between these XML Schema primitives and platform-specific primitives, i.e. a string in XML Schema maps to a System.String in .NET, and to a java.lang.String in Java. Using the XML Schema primitives, as well as structures and arrays built from those primitives, it is possible to construct more complex data types, described in XML Schema, that can be mapped with high-fidelity from one platform to another. These data types can then be employed in WSDL documents for use in the Web service.
This is the core of what is known as the "WSDL first" design: by using XML Schema types to define the data types used in the Web service you increase the probability that you will use data types that can be mapped from one platform to another.
The WSDL First approach is also sometimes called the "Schema First" approach. Even though the two terms are typically used interchangeably, there is actually a small distinction between the two terms. What we are advocating in this paper is that architects and developers consider building up the contract using WSDL definitions before they build the underlying code to support the service. To build the WSDL file developers can either create XML Schema definitions that are specific to the interface they are used with, "WSDL First" design, or they can use XML Schemas that are already defined within their application domain, "Schema First" design. This paper will use the "WSDL First" terminology.

Figure 3. WSDL First Web service development
The challenge with the WSDL First approach is that current tools in production today do not promote this practice. It's definitely possible, but not easy. Visual Studio provides a Schema editor and an XML editor, but no WSDL editor. Eclipse also does not include a WSDL editor. Fortunately both environments do provide a capability to generate Web service skeleton code, in addition to client-proxy code from a WSDL file.
You can use any tool to create your own WSDL file including VI and Notepad. Instead of directly editing the text, you can also use specialized tools, such as Altova's XmlSpy, that have WSDL designers to help with the task. However, even this may not be a solution as many developers are not able to "think in WSDL."
One solution to this problem is to quickly prototype a Web service interface using the Implementation First approach. We use the dynamic WSDL generation features of ASP.NET, or IBM WSDK, to create a template WSDL file. Then we can begin development using the WSDL First approach, tweaking the interface as required. This process iterates until the WSDL is final.
As you can see from Figure 3 above, there are three high-level steps for creating Web services using the WSDL First approach:
- Create the WSDL document
- Implement the WSDL document
- Create the Web service
- Create the Web service client
Sub-steps A and B of step 2 can be done in any order you wish. Because both depend on the WSDL document, it is only important that the WSDL document be created first before A or B is done.
The rest of this section will walk through the steps to developing the first
Web service sample following the WSDL First process. The complete source code
for this sample can also be found in the download accompanying this paper.
Creating the WSDL from Visual Studio .NET (Implementation First)
Before we go into the WSDL First approach of creating Web services we will look at the Implementation First development model in Visual Studio .NET. The reason that we are demonstrating this method first is that creating a WSDL file from scratch is hard. Using the WSDL file generated from the Implementation First approach to "jump-start" the development process is a much simpler alternative given the tools at our disposal. Imagine having to type this all out by hand:
<?xml version="1.0" encoding="utf-8"?>
<definitions xmlns:http="http://schemas.xmlsoap.org/wsdl/http/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:s="http://www.w3.org/2001/XMLSchema"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:tm="http://microsoft.com/wsdl/mime/textMatching/"
xmlns:mime="http://schemas.xmlsoap.org/wsdl/mime/"
xmlns:s0="http://example.org/"
targetNamespace="http://example.org/"
xmlns="http://schemas.xmlsoap.org/wsdl/">
<types>
<s:schema elementFormDefault="qualified"
targetNamespace="http://example.org/">
<s:element name="Add">
<s:complexType>
<s:sequence>
<s:element minOccurs="1" maxOccurs="1" name="x"
type="s:int" />
<s:element minOccurs="1" maxOccurs="1" name="y"
type="s:int" />
</s:sequence>
</s:complexType>
</s:element>
<s:element name="AddResponse">
<s:complexType>
<s:sequence>
<s:element minOccurs="1" maxOccurs="1" name="AddResult"
type="s:int" />
</s:sequence>
</s:complexType>
</s:element>
</s:schema>
</types>
<message name="AddSoapIn">
<part name="parameters" element="s0:Add" />
</message>
<message name="AddSoapOut">
<part name="parameters" element="s0:AddResponse" />
</message>
<portType name="Service1Port">
<operation name="Add">
<input message="s0:AddSoapIn" />
<output message="s0:AddSoapOut" />
</operation>
</portType>
<binding name="Service1Soap" type="s0:Service1Port">
<soap:binding transport="http://schemas.xmlsoap.org/soap/http"
style="document" />
<operation name="Add">
<soap:operation soapAction="http://example.org/Add"
style="document" />
<input>
<soap:body use="literal" />
</input>
<output>
<soap:body use="literal" />
</output>
</operation>
</binding>
<service name="Service1">
<port name="Service1Soap" binding="s0:Service1Soap">
<soap:address
location="http://localhost/NetWSServer/Service1.asmx" />
</port>
</service>
</definitions>
Of course for the WSDL-wiz, this exercise is trivial, but for the rest of us,
it would take forever to learn the 51-page WSDL specifications. This is why we use the Implementation First to start off because writing code to create a Web service is the simplest method for developers.
First create a C# ASP.NET Web Service project in Visual Studio .NET. Name the project WebService1WSDL.

Figure 4. Visual Studio .NET New Project dialog box
Next, open the code for Service1.asmx. Uncomment the HelloWorld method and replace the method with this one:
[WebMethod]
public int Add(int x, int y)
{
return -1;
}

Figure 5. Implementation First Web service code
Build the project and make sure there aren't any errors. Next, right click on Service1.asmx and set the page as the start page. You can now press F5 and view the Web service test page as shown in Figure 6.

Figure 6. Web service test page
It's important to realize that the ASMX file is the actual Web service. The page you are looking at is generated by the framework to document the Web service, and to allow the developer to test the Web service without having to manually create a client application. The test functionality is only available when you view the page locally, and does not work for Web services that take complex data types as input parameters. For security reasons, you should remember to disable this test page once you deploy your Web service to a production machine.
Next, click on the Service Description link on the top right side of the page. This will open another web page showing you the generated WSDL for your service. The WSDL generation function is always available unless you specifically disable it. Save the generated WSDL to a file on your local drive and name it WebService1.wsdl.

Figure 7. Framework generated WSDL file
You have just created a WSDL file, without having to learn any WSDL specifications!
Another important tip here is that since we generated the WSDL file from this temporary project, the location of the Web service in the WSDL document is hard coded to point to this temporary project. While this does not affect the Web service, the clients that use this WSDL file will use this reference as the location of the Web service. Thus, it is important that you change this value before deploying this WSDL file to our web site. We will change this reference later once we know the actual location of our Web service.
If you forget to change this location and client applications have already been built, you can still fix the reference by modifying the location that client references point to. Both .NET and WebSphere Web service client proxies allow setting a URL property. This is also useful when moving from development to production where the final end point of the service is the only thing you want to change.
Since the Web service we're building is simple, our generated WSDL file does not require any more tweaking. The next step is to create the actual .NET Web service.
Implementing the .NET Web Service (WSDL First)
Using the WSDL generated in the previous step, we will now create a new .NET Web service.
In order to go from the WSDL file to a source code file, we will use a console application called wsdl.exe to generate the code. This tool will parse a WSDL file and any other external files to create a single source code file containing all classes, methods, and types required to implement our Web service. Wsdl.exe is installed along with Visual Studio .NET 2003 (and the .NET SDK). To use the tool, you will need to open the Visual Studio .NET 2003 Command Prompt, which is by default located in the Start menu, All Programs, Microsoft Visual Studio .NET 2003, Visual Studio .NET Tools. Once open, navigate the command prompt to where you previously saved WSDL file.
Execute the following command to have wsdl.exe generate our Web service source file.
wsdl.exe /server WebService1.wsdl

Figure 8. Visual Studio .NET 2003 Command Prompt executing wsdl.exe
Notice that the utility outputs a message indicating that Service1.cs has been successfully created. This file will be the starting point for our Web service.
The file generated by wsdl.exe is only a template of the method that we want to implement; hence, it needs to be modified in order to work properly. The current wsdl.exe command always generates an abstract class for the Web service when it is executed with the /server option. We'll convert this to a concrete class by removing the abstract keyword and providing an implementation for the Add method. We will also put the class in the WebService1 namespace. The resulting code looks like the following:
namespace WebService1
{
/// <remarks/>
[System.Web.Services.WebServiceBindingAttribute(Name="Service1Soap",
Namespace="http://tempuri.org/")]
public class Service1 : System.Web.Services.WebService {
/// <remarks/>
[System.Web.Services.WebMethodAttribute()]
[System.Web.Services.Protocols.SoapDocumentMethodAttribute(
"http://tempuri.org/Add", RequestNamespace="http://tempuri.org/",
ResponseNamespace="http://tempuri.org/",
Use=System.Web.Services.Description.SoapBindingUse.Literal,
ParameterStyle=
System.Web.Services.Protocols.SoapParameterStyle.Wrapped)]
public int Add(int x, int y) {
int result;
result = x + y;
return result;
}
}
}
You might wonder, why not just subclass the generated abstract class,
instead of converting it to a concrete class? There's a good reason. The wsdl.exe tool generates code that is decorated with attributes that are used by .NET's XML serializer and Web services runtime to map from objects to XML and back. For example, an attribute in our example uses the http://tempuri.org namespace for the generated XML document. These attributes are not inherited by subclasses. Therefore, sub-classing the abstract class, we would need to cut-and-paste all of these attributes on our concrete class.
So instead of duplicating all the attributes by hand, it is simpler to just edit the file directly. Of course, this means that if the WSDL changes, you will need to regenerate the source code for the WSDL file, and if not done carefully, this process may erase all our existing code. You will have to manually copy the Web service implementation code from your old file to the new file.
Now that we have the Web service source code ready, it is time to create our Visual Studio solution. Create a new Visual Studio .NET C# ASP.NET Web Service project and give it the name WebService1.
Once you have your project created, copy the Web service implementation code Service1.cs created earlier to the directory where Visual Studio generated the Web service files. This is usually in c:\inetpub\wwwroot\WebService1.

Figure 9. Windows Explorer showing the Web service project files
The sample Web service, Service1.asmx, was generated as a part of the Visual Studio project wizard. Since the wsdl.exe command only generates the template implementation code and not the entry point (the ASMX) file, we want to reuse the VS generated Service1.asmx instead of creating our own. However Service1.asmx already has a corresponding source file. An easy way to combine the ASMX file with our implementation code is by simply deleting the implementation code generated by VS (Service1.asmx.cs) and renaming our implementation code to that. Make sure that Service1.asmx and Service1.asmx.cs are not open in Visual Studio before you do this. So, delete the current Service1.asmx.cs and then rename our Service1.cs to Service1.asmx.cs.
To verify that the code transplant worked, select Service1.asmx in Solution Explorer in Visual Studio and click the View menu, and then click Code. You should now see the template code with the Add method implementation we modified earlier displayed in Visual Studio .NET.
Finally, to test that the Web service is working properly, right click on Service1.asmx and click Set As Start Page. Then go to the Debug menu, and click on Start to build the project and to open Service1.asmx in your browser. Verify that your Web service works correctly using the test page.

Figure 10. Web Service Add test page

Figure 11. Response from the Web service of adding 12 and 45
To wrap up the .NET Web service, we now need to go back to the original WSDL document to make some minor changes. As mentioned before, the WSDL document is currently pointing at our temporary project Web service. Now that we have finished creating our real Web service, we can modify the location reference to point to this Web service. You can do this by opening up the original WSDL document and then replacing the soap:address element's location attribute to point to the location of this new Web service. The new soap:address element should look similar to the following:
<port name="Service1Soap" binding="s0:Service1Soap">
<soap:address location="http://localhost/NetWSServer/Service1.asmx" />
</port>

Figure 12. Location of Web service being modified in the WSDL file
This concludes building a .NET Web service using the WSDL First approach. Next, we will build the WSDK Web service client to consume this .NET Web service.
Implementing the WSDK Web Service Client
Now that we have a Web service implemented, it's time to create a client to consume the Web service. Since this paper is about interoperability, we will consume the .NET Web service using a JSP page running within IBM's WebSphere Application Server.
Start Eclipse and create a new Dynamic Web Project. Give it the project name WebServiceClient1 and name the EAR project file WebServiceClient1Ear.

Figure 13. Eclipse showing the WebServiceClient1 project
Next, add the WSDL file to the WebServiceClient1 project. You can do this by dragging and dropping the file directly into the project in the Eclipse Navigator pane.
Now we want to generate a Java proxy for the Web service. Similar to how Visual Studio .NET creates a proxy class when adding a web reference to a project, the WSDK Tools will create a set of Java files that make calling the Web service easier than manipulating the network stream directly. Because we had already added the WSDL document in the project, you can create the proxy by right clicking the WSDL document, point to the Web Services menu, and then click on Generate Client. This will bring up the WSDL to Java Bean Proxy wizard as shown below in Figure 14.

Figure 14. WSDL to Java Bean Proxy wizard
In the first dialog, make sure to check the Test the generated proxy check box. This will generate the test JSP page (similar to the test page generated from Service1.asmx when creating the Web service in Visual Studio) that we will use to verify the proxy classes generated. The default options for the rest of the wizard will work so click Finish.
After Eclipse completes generating all the necessary files, the following test page is displayed in the Eclipse main window.

Figure 15. Eclipse IDE showing the test JSP page
Click on add(int,int) in the Methods pane and provide 2 numbers to be added in the Inputs pane. You should see the sum of your 2 numbers in the bottom Result pane. Behind the scenes, this JSP page is calling the Web service proxy class, generated earlier by the WSDK Web service wizard, to call our .NET Web service. Because we had changed the Web service location reference in the WSDL document, our Java client knows exactly where to find the Web service we created in step 2 earlier. If the displayed sum of your 2 numbers is correct, then this successfully verifies that the Java proxy was generated properly and is actually talking to the .NET Web service.
Another method to verify the connection between service and client is to set a break point in the Web service code in Visual Studio .NET and then run the service in debug mode. In the Java side, once you execute the add function in the JSP page, you should see Visual Studio .NET stop the execution of the Web service and break at the point you specified.
At this point, we have verified that the Java proxy class generated from the WSDL is functioning properly. We also used the test page generated by the WSDK wizard to test calling the .NET Web service from Java. Since both are working properly, this completes both the .NET Web service and the Java Web service client demo of Web Service 1.
Though we do not describe in detail the steps
for creating the .NET Web service client and the Java Web service server, the
sample code accompanying this article does include implementations of both
server and client, in both .NET and Java. If you want to generate these
yourself, you can find other tutorials for those steps.
Web Service 2: Ratings and Reports
The second sample builds on the first by creating a Web service that uses a much more complex data schema. Our goal for this sample is to show interoperability between .NET and WebSphere when using complex data types. In the schema for this sample, there is a combination of complex types, simple types, enumerations, restrictions, arrays, and types that inherit from other types in addition to the standard XML Schema types. The differences between the two platforms and the issues in developing interoperable Web services are more apparent in this sample because of this increased complexity.
Scenario
The company, Stuff Sellers, sells various products to various business types. Each business is allowed to submit reviews of the products they buy. Web Service 2 takes the scenario of a ratings service that allows users to submit a report for a given rating or to obtain a list of all reports for a given rating identified by a number. In this case a report can be seen as analogous to a review and the sum of the reviews is used to generate the final rating.
Data Schema
The following diagram depicts the high level elements of the data schema.

Figure 16. Main elements of Web Service 2 data schema
The top level element is Ratings. Each Ratings element contains an array of ReportSet elements (encapsulated in the ReportSetArray type). Then each ReportSet element contains an array of Report elements (encapsulated in the ReportArray type). All three of these top level elements are data types that inherit from the MyBase type. To see the actual XML Schema definition for this data schema, refer to the WebService2SharedTypes.xsd file in the samples download.
As is the case with WSDL, there are two ways to generate an XML Schema. The first is to manually design the schema using a schema designer (in the case of XML Schema, Visual Studio does include a designer). The second is to infer the schema from an existing .NET type, using the xsd.exe utility. And as with WSDL, these two techniques can be combined in an iterative approach to tweak a schema so that it looks just right.
In some cases, the data schema has been previously defined, and exists independently of the Web service implementation or interface. This may be the case when you are assigned to create a Web service based on the design of a current system. Whether you create the schema or are provided with an existing one, the data schema should be described in a self–standing XML Schema XSD file, to allow for modularity and re-use.
The following is a class diagram depicting the XML Schema defined in the data schema for this Web service. In the same code, the schema is defined in the file WebService2SharedTypes.xsd. The code generated from the data schema (the XML Schema file) on each platform should follow a class structure similar to this diagram.

Figure 17. Class diagram of the data schema in Web Service 2
Web Service Definition
In the first Web service, we used the .NET Framework to generate the initial template WSDL file. Because our Web service was simple, that was the only step we needed to do to create the WSDL. Unfortunately, this Web service is not as simple and thus requires some manual tweaking. Including references to our data schema, changing the namespace, and creating the proper messages for the portTypes are just some of the changes we had to make to the template WSDL file in order to maintain interoperability.
The WSDL document for this Web service defines two operations: GetRatings and SubmitReport. GetRatings returns a Ratings type if the ID provided matches a given rating. The SubmitReport operation is used by clients to submit a new Report associated with a specific Ratings and ReportSet. You can see the WSDL definition of these operations in WebService2.wsdl in the samples download.
There are two ways to include XML Schema definitions in WSDL files: you can define the schema inline in the WSDL file or by referencing your XML Schema files in your WSDL file using the xsd:import element. Because inline definitions are part of the WSDL file, they are simple to maintain. However, since a data schema describes data and not the Web service interface, and is sometimes used independently of the web service interface, it is more logical to separate the two definitions into two separate files. If your Web service is simple and doesn't require many complex data types, then inline schema will work fine (as in Web Service1), but in general most Web services should separate the data schema from the Web service definition.
In this Web service, we decided to use the xsd:import method to reference the external XML Schema file, WebService2SharedTypes.xsd from the WSDL file, WebService2.wsdl. In the WSDL file, it looks like this:
<types>
<xs:schema targetNamespace="http://example.org/">
<!-- Import the Shared Types -->
<xs:import namespace="http://example.org/sharedtypes"
schemaLocation="WebService2SharedTypes.xsd"/>
<!-- Import the Message Parameters -->
<xs:import namespace="http://example.org/interface"
schemaLocation="WebService2Interface.xsd"/>
</xs:schema>
</types>
. . .
Implementation
To create the Web service template code in .NET, run wsdl.exe with the following parameters:
wsdl.exe WebService2.wsdl WebService2Interface.xsd
WebService2SharedTypes.xsd
Notice that wsdl.exe requires the input WSDL file and all of the included
XSD files to be specified on the command line together. When importing an XSD into a WSDL, it is possible to provide a schemaLocation attribute. According to the WSDL specification, this attribute serves as a "hint" for the location of the schema, and the hint may or may not be followed by tools that interpret the WSDL file. In this case, wsdl.exe does not use the schemaLocation hint, so the external schema files must be specified on the command line. On the other hand, the IBM WSDK tools do utilize the schemaLocation hint and will load the files directly when specified.
An important detail to pay attention to is that the ID element of MyBase is defined with type xsd:int and includes the minOccurs=0 attribute. The XML Schema definition of MyBase looks like this:
<xs:complexType name="MyBase">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="1" name="ID" type="xs:int"
nillable="true" />
</xs:sequence>
</xs:complexType>
When minOccurs=0, this indicates that the ID property can be left out of the resulting XML document.
This causes a problem for the .NET platform. In .NET, the xsd:int maps to Int32, which is a value type, and value types cannot be NULL. Basically this means there is no way to determine whether the ID property has been set or not since all values of Int32 are valid values. The .NET Framework resolves this problem by creating another variable named IDSpecified of type Boolean. This variable is checked by the .NET XML Serialization logic to determine whether the ID variable has been set or not, essentially giving ID the NULL/not NULL value. Therefore whenever you attempt to access the ID variable, you should always check or set the IDSpecified variable first. For more information on this usage pattern, see the MSDN documentation for the XmlIgnoreAttribute class.
The following is what the MyBase type gets translated to in C# code:
[System.Xml.Serialization.XmlTypeAttribute(Namespace=
"http://example.org/sharedtypes")]
[System.Xml.Serialization.XmlIncludeAttribute(typeof(Report))]
[System.Xml.Serialization.XmlIncludeAttribute(typeof(ReportSet))]
[System.Xml.Serialization.XmlIncludeAttribute(typeof(Ratings))]
public class MyBase
{
public int ID;
[System.Xml.Serialization.XmlIgnoreAttribute()]
public bool IDSpecified;
}
This issue does not occur when using the WebSphere sample, because when an
xsd:int is used with minOccurs=0, the WSDK tools generate a variable of type java.lang.Integer instead of the native int Java type. The java.lang.Integer type is a reference type, and it is possible for a variable of this type to take the NULL value to indicate that it has not been set. Using the tools provided in the WSDK, the following is what the MyBase type gets translated to in Java code:
public class MyBase implements java.io.Serializable {
private java.lang.Integer ID;
public MyBase() {
}
public java.lang.Integer getID() {
return ID;
}
public void setID(java.lang.Integer ID) {
this.ID = ID;
}
}
Another difference that is evident when comparing the
C# code generated from the XML Schema, to the Java code generated for the same schema, is the inclusion of code attributes in the C# code. As we said earlier, these are used by the XML Serializer in .NET to help in mapping from class instance to XML. Java also requires similar "metadata". In the case of the Web services runtime in WSDK, this metadata it is stored independently, in an XML file that defines the type mappings. See the WSDK documentation for more information.
Another point of interest: if you examine the classes generated by either the .NET tools or the WSDK tools, you will find that the generated data types may not be what you, as a developer, would write without considering interoperability. Examine the Ratings.java class generated by WSDK. Excluding some housekeeping code, it looks like this:
public class Ratings extends org.example.MyBase implements java.io.Serializable {
private java.lang.String description;
private int confidenceLevel;
private java.util.Calendar expiration;
private org.example.ReportSetArray allReports;
public Ratings() {
}
public java.lang.String getDescription() {
return description;
}
public void setDescription(java.lang.String description) {
this.description = description;
}
public int getConfidenceLevel() {
return confidenceLevel;
}
public void setConfidenceLevel(int confidenceLevel) {
this.confidenceLevel = confidenceLevel;
}
public java.util.Calendar getExpiration() {
return expiration;
}
public void setExpiration(java.util.Calendar expiration) {
this.expiration = expiration;
}
public org.example.ReportSetArray getAllReports() {
return allReports;
}
public void setAllReports(org.example.ReportSetArray allReports) {
this.allReports = allReports;
}
}
For the primitive data members, of type int and string, perhaps they reflect what any designer
might hand-author: following JavaBean conventions with getters and setters wrapped around a private member. But then some of the differences appear. The date value is handled by a Calendar, not a java.util.Date. And, an Array is wrapped by a custom class, also accessible via a getter/setter pair. This generated class may not be what you would write yourself, but it does the job, and it has the added advantage of being interoperable. You could make the same statements about the code generated by the .NET tools.
We followed the general steps outlined in the section for Web Service 1, above, to build two Visual Studio projects: one for the client, and one for the server. We did likewise with the WSDK to build two WebSphere projects. All of these clients and servers are mutually interoperable. Compile and run the Visual Studio projects and the Eclipse projects in the samples download to see all of this in action. Be sure to check the Readme for the samples download before proceeding.
This sample explored the use of complex data types in an interoperable Web service. The W3C XML Schema plays a key role in defining the message types and data elements to be exchanged. This section discussed how to develop an XSD for a complex data type, and how to employ that XML Schema in a WSDL document. This section also pointed out some of the edge cases to be aware of, for example, the difference between value and reference types in .NET, and the implications that this difference has on XML Serialization.
In the next sample, we will expand on the ideas from this sample and explore interoperability using extensible data elements.
Web Service 3: Product Search
Most Web services employ a fixed data schema—that is, the types of data sent over the wire are known at design time. But sometimes a static data schema does not fulfill the requirements for the application. Consider the following business scenario.
Scenario
As mentioned in Web Service 2, Stuff Sellers sells various products to both consumers and other businesses. Because the company sells so many different products, the manager has asked us to create a Web service that will make it easier to search the database of products. Our search will be used indirectly by consumers through the Internet store front, and directly by other businesses.
The manager would like the Web service to support the following three requirements:
- Allow dynamic data. Because Stuff Sellers often adds new product types to their database, the Web service definition should be flexible enough to add support for the new types without breaking existing clients.
- Support basic processing. Companies looking for products from Stuff Sellers may be only interested in products with a certain property. For example, the discount store may be looking for products that are less than 50 cents. The Web service should be able to return data and allow the client to do a simple check on the results for this property without too much difficulty.
- Be extensible. Stuff Sellers may need to modify the Web service in the future and would like the Web service to be able to easily support new features while minimizing the impact on existing clients.
In addition to these requirements, the manager would like the Web service interface to be as simple as possible. Specifically, the Web service should have only a single entry point.
Looking over the products that Stuff Sellers currently sells, we find that all products at a minimum have a Name, Description, Price, and a SKU. These attributes will make up the base properties for all our products. In addition, each product also has its own unique set of attributes. For example a DVD movie has a Region Encoding, a Video Format, a Language, and a Date of Release. A Book product has a list of Authors, a Publisher, an ISBN, and a Published Date. Therefore, the base product type will expose all of the properties that are common across product types, and will allow extensions for properties that are specific to particular product types.
Data Schema
The following is a class diagram of the data schema defined for Web Service 3.

Figure 18. Class diagram of the data schema in Web Service 2
The XML Schema type definition for SearchResult (in WebService3SharedTypes.xsd) is defined as the following:
<xs:complexType name="SearchResult">
<xs:sequence>
<xs:element minOccurs="1" maxOccurs="1" name="SKU"
type="xs:string"/>
<xs:element minOccurs="1" maxOccurs="1" name="Price"
type="xs:decimal" />
<xs:element minOccurs="1" maxOccurs="1" name="Name"
type="xs:string"/>
<xs:element minOccurs="1" maxOccurs="1" name="Description"
type="xs:string" />
<xs:element minOccurs="1" maxOccurs="1" name="ProductType"
type="xs:string" />
<xs:any minOccurs="1" maxOccurs="1" processContents="lax" />
</xs:sequence>
</xs:complexType>
As you can see, SearchResult is the parent type that represents all products found by the Web service.
SearchResult contains properties that are common to all product types. In addition, SearchResult also contains an xsd:any element, which acts as a wildcard. An XML file that validates to this schema can include any XML element at that location. For our purpose, the xsd:any element will contain one of the product property types that can be returned by the Web service. We have defined three such product property types in WebService3ExtendedProperties.xsd: DvdProperties, BookProperties, and CDProperties. In practice, a client application will access the common properties by checking SearchResult, and will access the extended properties for that product by checking the member variable that contains the product specific properties types.
An alternative to using xsd:any in the schema to match any XML element is to employ a string element in the schema, which will contain dynamically generated XML. Using a string is a similar "wildcard" approach. The difference is that the XML contained within the string will be "escaped" for transmission, and so will be opaque to XML parsers, which is not what we want. It is cleaner to integrate the dynamic XML as part of the XML document instead of escaping it into a string element. In either case, there is a bit of extra work required, to generate the XML on the sending side, or to parse it on the receiving side.
Web Service Definition
Just as in the second sample, the WSDL document for this Web service is separated into two files: WebService3.wsdl and WebService3SharedTypes.xsd. WebService3.wsdl contains declarations that define the Web service and WebService3SharedTypes.xsd is an XML Schema file that contains the data types used by the Web service. The following is a sample capture of the SOAP message returned by the Web service to the client.
<?xml version="1.0" encoding="utf-8" ?>
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<soap:Body>
<SearchResponse xmlns="http://example.org/sharedtypes">
<SearchResult>
<SearchResult>
<SKU>B05502HB9I</SKU>
<Price>14.99</Price>
<Name>Spain's History</Name>
<Description>Short documentary on the history of the
Spain.</Description>
<ProductType>DVD</ProductType>
<DvdProperties xmlns="http://example.org/resulttypes">
<Region>EUROPE</Region>
<Format>PAL</Format>
<Language>Spanish</Language>
<ReleaseDate>2000-05-14</ReleaseDate>
</DvdProperties>
</SearchResult>
<SearchResult>
<SKU>A04D5E87RJ</SKU>
<Price>20.00</Price>
<Name>Spain's History</Name>
<Description>Companion coffee table book to the documentary
"Spain's History".</Description>
<ProductType>Book</ProductType>
<BookProperties xmlns="http://example.org/resulttypes">
<Authors>
<Author>Mark Person</Author>
</Authors>
<Publisher>BookPub Central</Publisher>
<ISBN>0459756212</ISBN>
<PublishedDate>2003-08-08</PublishedDate>
</BookProperties>
</SearchResult>
</SearchResult>
</SearchResponse>
</soap:Body>
</soap:Envelope>
There is also a third file, WebService3ExtendedProperties.xsd,
which isn't imported into the WSDL, but is essential for the Web service to generate a response, and for clients to be able to interpret the response from the Web service. This file contains the definitions of the dynamic part of the data: the extended properties for the product types.
The advantage of keeping the product types separate from the types used by the Web service is the ability to extend the product types, without modifying the interface. Eventually Stuff Sellers will expand its business and start selling other types of products. Since search results will contain these new products, adding the new products in a simple way is a crucial requirement. With our design, supporting new types is a simple matter of extending the Web service implementation to return the new types and extending the data schema defined in WebService3ExtendedProperties.xsd. Publishing the new XSD file to the web and letting customers know of the change are the last steps needed. There is no change needed to the WSDL file.
Web service clients that do not wish to use the extended properties or simply pass on the extended properties to other services can chose to ignore the extended properties. At runtime, these clients need not de-serialize the XML blob into objects. For example, if an application is written to filter products based only on price, then it doesn't matter what type of product is returned. In this case, the client only needs to check the base property Price of the SearchResult type and can safely ignore the extended properties.
With the use of xsd:any, the Web service has the flexibility to add new features without having to break existing clients. New Web service clients can use the new product types while existing applications will simply ignore the new product types. Even if existing product types are removed, the existing Web service clients will still function properly because they will simply not execute the code pertaining to the old products. This design provides the best of both worlds, where response messages can be extended for new applications, while still allowing existing applications to function properly.
Implementation
Converting between XML and corresponding instances of objects is called "XML serialization", or "XML binding". The process of converting between parameters to a Web service call, and the XML sent over the wire in a Web service request or response, is usually done automatically by the Web services runtime. However, when using schema extensions that are not defined in the WSDL (or its imported XSDs), this XML serialization and de-serialization must be done manually. .NET exposes tools and programming interfaces that enable this.
IBM WebSphere does not expose public interfaces to manually perform XML serialization. The Java client and server require an add-on capability to perform the Java-to-XML binding. One such add-on is the JAXB API that is part of Sun's JWSDP. Installing the JWSDP will give you the JAXB compiler, which can generate Java class from an XML Schema, similar to the xsd.exe utility for .NET. Using the classes to reference the data types is much simpler than directly manipulating XML elements. In JAXB, the generated data type classes are also responsible for "marshalling" or "serializing" to, and "unmarshalling" or "deserializing" from, XML files that conform to that XSD.
The .NET Framework SDK also includes a tools and a framework for binding XML data to .NET classes. The Xsd.exe tool parses an XSD file to create a corresponding source code file that contains the data type definition classes. At runtime, applications can use the System.Xml.Serialization namespace of classes to create an object graph from an XML stream, or vice-versa.
For example, at compile time, to generate C# classes from the WebService3ExtendedProperties.xsd schema, use the following command:
xsd.exe /classes WebService3ExtendedProperties.xsd
And then at runtime, to create the object graph from a file, use these few lines of code:
FileStream fs = new FileStream(path, FileMode.Open);
XmlSerializer s= new XmlSerializer(typeof(BookPropertiesType));
BookPropertiesType props;
try {
props= (BookPropertiesType) s.Deserialize(fs);
}
finally {
fs.Close();
}
Normally, for data types used in Web services interfaces, the steps of creating the data type
classes and performing the serialization are performed automatically for you: the former by the wsdl.exe tool or the "Add Web Reference" in Visual Studio, and the latter by the web services runtime in .NET. When you pass a parameter to a web service, the parameter is automatically serialized to XML for transmission across the network. The use of xsd.exe is necessary here to create the classes because the WebService3ExtendedProperties.xsd schema is not explicitly included in the web service interface definition.
What about the serialization at runtime? When parsing a Schema, xsd.exe will map xsd:any elements to fields of type XmlElement. By modifying the generated classes, changing the type of the field to System.Object rather than System.Xml.XmlElement, and decorating the field with XmlElementAttribute attributes, we can tell the framework to map the XML data to specific .NET datatypes, rather than a generic XmlElement. For example, in this snippet, the Any field will map to one of the three flavors of extended properties.
[System.Xml.Serialization.XmlElementAttribute(ElementName="DvdProperties",
Type=typeof(NetWSServer3.DvdPropertiesType),
Namespace="http://example.org/resulttypes")]
[System.Xml.Serialization.XmlElementAttribute(ElementName="BookProperties",
Type=typeof(NetWSServer3.BookPropertiesType),
Namespace="http://example.org/resulttypes")]
[System.Xml.Serialization.XmlElementAttribute(ElementName="CDProperties",
Type=typeof(NetWSServer3.CDPropertiesType),
Namespace="http://example.org/resulttypes")]
public object Any;
With these modifications to the generated classes, the .NET runtime will automatically and implicitly serialize the Product property object types to and from XML. Without this capability, the developer would have to explicitly serialize these classes to XML. And in fact, this is the approach taken with WebSphere for the extended properties types. (See the sample code for details).
While developing this sample, one consideration was to determine whether to make the ProductType an enum or just a string. The benefit of an Enumeration is that the different types are explicitly stated and thus cannot be confused. However in the end, the decision not to use enum was taken because of the requirement for extensibility: we want the flexibility to create additional and possibly remove existing product types without breaking existing clients. If ProductType was defined as an enum, then future product types that get passed to old clients would break. Therefore a string was used instead because this allowed the flexibility to expand the product lines while keeping existing Web service clients still working.
As with Web Service 2, the data types generated here by the tools probably will not match what a developer might write when modeling the problem in code. However, here again, the key advantage of starting with WSDL and generating code is interoperability.
As with Web Service 2, we followed the general steps outlined in the introduction of this article to produce client and server projects for both Visual Studio and the WebSphere web services SDK. And here again, the resulting clients and servers are fully interoperable. Ok, enough description. Compile and run the Visual Studio projects and the Eclipse projects in the samples download to see the extensibility of Web Service 3 of this in action.
Web Service 3 showed the use of complex data types, statically included as well as dynamically included in a WSDL. The support for extensible types allows for the flexibility to expand and to modify the interface with minimal changes required to the Web service and to the Web service clients.
Conclusion
With the three Web services shown in the paper, we can see that it is definitely possible to create interoperable Web services using complex data types. The easy path through the developer tools—the "Implementation First" approach—often leads to interoperability challenges. However, by defining the Web service interface first, in WSDL, and generating clients and servers from that interface definition, many interoperability pitfalls can be avoided. Even though we have shown the "WSDL First" approach specifically for .NET and WebSphere, the concepts illustrated apply to interoperability across all platforms.
Hand-authoring WSDL is not easy. This paper also explored the approach of iteratively developing and refining WSDL files and W3C XML Schema definitions, using the prototyping tools included in Visual Studio .NET and the WSDK.
Finally, the paper provided tips and pointers about likely pitfalls on the path to creating interoperable and extensible Web services. Armed with these ideas of creating interoperable Web services, we may eventually achieve the dream of ubiquitous access to any system, regardless of platform and architecture.
The following is a listing of recommendations and tips reviewed in this paper.
Recommendations/Tips
Working with WSDL Documents
- When coding the WSDL by hand, be very careful of the current namespace context. The string for the namespace must be exactly the same for all references to the same namespace.
- If your Web service must return a complicated data type for which the mapping to and from XML is not well defined, consider creating your own data type that represents the same data. This permits maximum portability while still allowing you to pass your necessary data.
- To promote modularity and re-use, use XSD import rather than inline schema definitions. See Web Service 2 and Web Service 3 samples for examples.
- Be careful of a data type's optional attributes in the XML Schema definition. Some of these can alter how the implementation code is generated. Refer to Web Service 2 for an example with the
IDdefinition. - The Web Services Interoperability (WS-I) Organization is the official organization that was formed to promote interoperable Web services across all platforms and languages. The organization created a specification for interoperability called the WS-I Basic Profile and provides tools to validate WSDL files against this specification.
- When an exception occurs in the Web service, a SOAPFault element is returned in the SOAP message. Typically the Web service framework will catch the SOAPFault and return its own Exception class. In the .NET Framework, SOAPFault is caught and wrapped in a
System.Web.Services.Protocols.SoapException. In WebSphere,com.ibm.ws.webservices.engine.WebServicesFaultis the exception that is thrown. Additional information about the error can be found by accessing the properties of the exception classes mentioned. - All XSD complex types are translated into classes. Because Java currently does not support enumerations, enumeration values are translated to public static string constants in the corresponding Java class.
- Some features of XSD schema cannot be represented well in some current platforms. One example is the unsigned integer types in XSD. Although .NET provides unsigned types, Java does not. Therefore using unsigned integers types within interoperable Web services is not recommended.
- Using arrays is tricky when working with boundary conditions. In .NET, if an empty array is serialized, only the header XML element is created. If a NULL array is serialized, it is completely ignored and nothing is serialized out as XML. On the other hand, Java will serialize the XML element for both cases. The difference is that for the NULL case, the Web services runtime within WebSphere will tag the XML element with an xsd:nil=true attribute to indicate that the array is null.
- When a WebSphere client de-serializes an empty .NET array, it will create an array with a NULL reference. If a WebSphere client deserializes a null .NET array, a
java.lang.NullPointerExceptionexception is thrown. - When a .NET client deserializes an empty WebSphere array, it will create an array that has Length equal to zero. When a .NET client deserializes a null WebSphere array, it will set the array reference to NULL.
Working with Wsdl.exe
When a WSDL file references other files (i.e. XSD files), you must explicitly provide the location of these files as arguments to wsdl.exe. For security reasons, wsdl.exe will not automatically load files from the schemaLocation references in the WSDL file. For example, if you're generating the code for Web Service 2, you will need to execute the following command:
wsdl.exe WebService2.wsdl WebService2Interface.xsd
WebService2SharedTypes.xsd
Refer to Web Service 2 for more information on this topic.
Wsdl.exe by default generates template code in C#. If you prefer another language (i.e. VB.NET), include the /l option with the command:
wsdl.exe /l:vb WebService1.wsdl
When generating a source file for a Web service (using the /server option),
the tool creates an abstract template class that is associated with the WSDL document. It is recommended that you modify this file directly rather than sub-classing the generated file. For more information on this topic, refer to Web Service 2.
Visual Studio .NET 2005, will support generating template source files from the WSDL directly in the IDE. In addition to this, if the WSDL document changes and the template file needs to be regenerated, the IDE will do so in such a way that any existing code already in the old template will carry over to the new one.
Working with Visual Studio .NET
When creating a Web service application in Visual Studio .NET, the generated project automatically provides the test page that appears when the Web service is accessed through the browser. Since we are developing Web services using the WSDL first approach, it is recommended that you disable this automatically generated WSDL and publish our own WSDL in a public location. To disable the automatically generated test page and WSDL, add the following into the <system.web> element of your web.config file of your project:
<webServices>
<protocols>
<remove name="Documentation" />
</protocols>
</webServices>
In addition to the wsdl.exe approach to creating a Web service proxy class,
you can also use the built in tools in Visual Studio .NET for a more user friendly approach. The Add Web Reference dialog box will ask you to point it to a WSDL file, which it will take in then generate a proxy class. Behind the scenes, the dialog essentially calls wsdl.exe in the background to process the WSDL file.
Unfortunately there is a bug in creating a client proxy if you use the Add Web Reference command in Visual Studio .NET 2002 to point to a WSDL document that uses xsd:import. If this is your case, always use the wsdl.exe command to generate the client proxy. This bug has been fixed in Visual Studio .NET 2003, which will properly retrieve all the imported files and then generate the client proxy class.
Creating the WSDL from Eclipse
With the tools provided by the WSDK, the Web services functionality in Eclipse is similar to Visual Studio. In Eclipse, you will need to create a Java Bean or EJB and use that as the template for a Web service. There are also some command line utilities you can use to generate Web service template files. You can find documentation in Eclipse to get more detailed instructions on how to do this.
Acknowledgements
http://msdn.microsoft.com/vstudio/java/interop/websphereinterop/default.aspx
Subscribe to:
Posts (Atom)